# 8.字符串:解决字符串匹配算法
# 8-1 字符串是什么
字符串是由n个字符组成的一个有序整体(n >= 0);字符串的逻辑结构和线性表相似,不同子处在于字符串针对字符集,也就是字符串中的元素都是字符,线性表则没有这些限制
在实际操作中,我们经常会用到一些特殊字符:
- 空串,指含有零个字符串,如:s = '',书面可以直接用Ø表示
- 空格串,只包含空格的字符串,它和空串是不一样的,可以包含多个空格,如 s = ' ',就包含了3个空格
- 子串,串中任意连续字符组成的字符串叫做该串的子串
- 原串通常也叫做主串,例如 a = 'BEI',b='BEIJING',c='BJINGEI'
- 对于子字符串a和b来说,b中含有a,所以可以称a是b的子串,b是a的主串
- 而c与a而言,虽然c中也含有a的全部字符,但是不是连续的'BEI',所以c和a没有任何关系
只有两个字符串的串值完全相同,这两个串才相等
字符串的存储结构与线性表相同,也有顺序存储链式存储两种
- 字符串的顺序存储结构,是一组地址连续的存储单元来存储串中的字符序列,一般是用定长数组来实现,有些语言会用\0来表示串值终结
- 字符串的链式存储结构,与线性表相似,但由于串结构的特殊性,如果也简单的将每个链结点存储为一个字符,会造成很大的空间浪费。因此,一个结点可以考了放多个字符,如果最后一个未被占满时,可以使用“#”或其他非串值字符补全
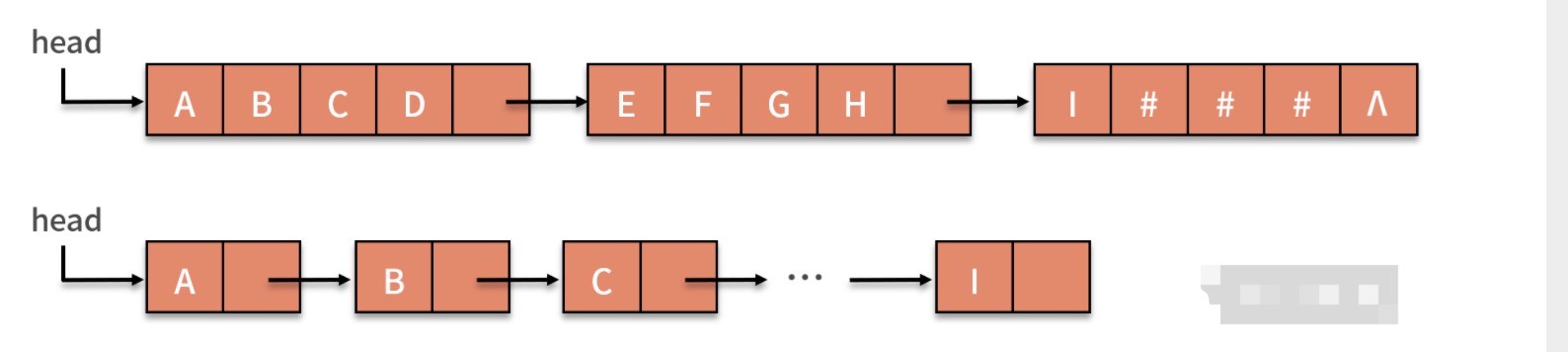
在链式存储中,每个结点设置字符数量多少,与串的长度、可以占用的存储空间以及程序实现的功能相关
- 如果字符串中包含的数据量很大,但是可用的存储空间有限,那么就需要提高空间利用率,相应的减少结点数量
- 而如果程序中存在大量插入、删除数据,如果每个结点包含的字符过多,操作字符就会变得很麻烦,为实现功能增加了障碍
因此,串的链式存储结构,除了在连接串与串操作时有一定的方便之处,总的说来,不如顺序存储灵活,在性能方面也不如顺序结构好存储
# 8-2 字符串的基本操作
- 字符串的和线性表操作很相似,区别在于,所有元素都是字符
- 线性表更关注单个元素的操作,如增删查;字符串更关注的是查找子串的位置、替换等操作
# 8-2-1 字符串的新增操作
- 字符串的新增操作和数组相似,都牵扯插入字符串之后字符的移挪操作,所以时间复杂度为O(n)
- 如果在字符串s1='123456' 正中间插入一个字符串s2='abc',则需要将456向后挪移3个字符位置,再插入
- 也存在一种特殊情况,比如再s1后面插入s2,则不需要移动位置,这时的时间复杂度为O(1)
# 8-2-2 字符串的删除操作
- 字符串的删除与数组的删除类似,也会牵扯到删除字符后的字符移挪操作,所以时间复杂度为O(n)
- 如果在字符串s1='123456' 正中间删除一个字符串s2='34',则需要将56需要向前挪移2个字符位置,时间复杂度为O(n)
- 也存在一种特殊情况,比如再s1删除56,则不需要移动位置,这时的时间复杂度为O(1)
# 8-2-3 字符串的查找操作
字符串s='goodgoogle',判断字符串t='google'在s中是否存在。这里要判断的不仅是字符是否存在,而且必须是连续的
# 8-2-3-1 子串查找(字符串匹配)
我们把主串的长度记为n,子串的长度为m,在主串里面找子串,且n是大于m的,所以字符串匹配的时间复杂度就是n和m的函数
主字符串为s='goodgoogle',子字符串为t = 'google'
- 首先,我么么从主串s的第一位开始,判断s的第1个字符是否与t的第一个字符相等
- 如果不想等,则继续判断主串的第2个字符与t的第一个是否相等,直到在s中找到与t第一个字符相等的字符时,再判断之后的字符是否与t后续字符相等
- 如果持续相等直到t的最后一个字符,则匹配成功
- 如果发现一个不等的字符,则重新回到前面的步骤,查找s中是否有与t的第一个字符相等
- s的第1个字符与t的第一个字符相等,则开始匹配的后续,但第4个字符匹配失败,则回到主串继续和t的第一个字符匹配
这种匹配方法,需要两层循环,第一层循环,去查找第一个字符相等的位置;第二层循环基于此去匹配后续字符是否相等,这样时间复杂度就变为O(nm)
function s8_1(){
let s = 'goodgoogle';//主串
let t = 'google';//子串
let isFind = 0;//是否有匹配
//a串第一个循环,注意,一般循环到第5位的时候,就不需要往后循环了,因为长度都已经不匹配了
for(let i = 0;i< (s.length - t.length + 1); i++){
//第一位是否匹配
if(s.charAt(i) == t.charAt(0)){
//记录相等时的字符长度
let jc = 0;
for(let j=0;j<t.length;j++){
//如果出现字段不等时,跳出循环
if(s.charAt(i+j) != t.charAt(j)){
break;
}
//相等字符长度
jc = j;
}
//如果相等的字符最后一位index与t的最后一位index一致,则符合要求
if(jc == t.length - 1){
isFind = 1;
}
};
};
//返回最终结果
return isFind;
}
# 8-3 字符串匹配算法的案例
假设有且仅有一个最大公共子串,比如a='13452439',b='123456',由于都包含456,则同时出现在a和b字符串中最长的子串为‘345’
假设a的长度为n,b的长度为m,可见时间复杂度是m和n的函数
- 首先,需要对a和b找到第一个共同出现的字符
- 然后,一旦找到第一个匹配的字符后,就可以同时在a和b中继续它后续的字符是否相等
- 这样,a和b都会被访问一次,全局还需要维护一个最长的子串变量
从代码结构来看,第一步需要俩层循环找到共同出现的字符,这就是O(mn)
一旦找到,就需要继续查找共同出现的字符串,这就又潜套了一层循环,可见最终的时间复杂度为O(nm2)
function s8_2(){
let b = '13452439';
let a = '123456';
let maxLength_str = '';
let max_len = 0;
//先循环对比第一个字符是否相等
for(let i = 0; i < a.length;i++){
for(let j = 0; j < b.length;j++){
//找到出现第一个相同字符的位置
if(a.charAt(i) == b.charAt(j)){
//然后比较顺序位置的字符是否都相等
for(let m = i,n=j; m < a.length && n < b.length; m++,n++){
if(a.charAt(m) != b.charAt(n)){
break;
};
//如果有更长的数值出现,重新赋值
if(max_len < m - i + 1){
max_len = m - i + 1
console.log(max_len,i,m)
maxLength_str = a.substring(i,m+1);
}
}
}
}
}
return maxLength_str;
}
# 8-4 总结
- 在线性表表中,大多以‘单个元素’作为操作对象
- 在字符串的基本操作中,通常以‘串的整体’作为操作对象
- 字符串的增删操作和数组很像,复杂度也与之一样。但字符串的查找就复杂多了,这点经常被考察
留下一个题,将c 重新按照 'blue is sky the'输出
function s8_3(){
let a = 'the sky is blue';
let len = a.length
let index = 0;
let word = '';
let result = '';
//循环
while(index < len){
//跳过空格(这里需要一个循环,而不是if)
while(index < len && a.charAt(index) == ' '){
index ++
}
//组合单词
while(index < len && a.charAt(index) !== ' '){
word = `${word}${a.charAt(index)}`;
index ++
console.log(word,index)
};
result = word + ' ' + result;
word = '';
}
return result.trim();
}