# 5.栈:后进先出线性表实现增删查
# 5-1 主要内容
- 栈是什么
- 栈对于数据的增删查处理
- 栈的一些案例
在有序排列的数据中,可以灵活进行增删操作,但是这种灵活在某种程度上破坏了数据的原始顺序,在某些场景下需要做一定的限制
被限制后的线性表就有了一些新的名字
# 5-2 栈是什么
栈是一种特殊的线性表,不同点体现在增和删的操作
栈的数据结点必须后进先出:新增只能在末端进行,删除也只能在末端进行;
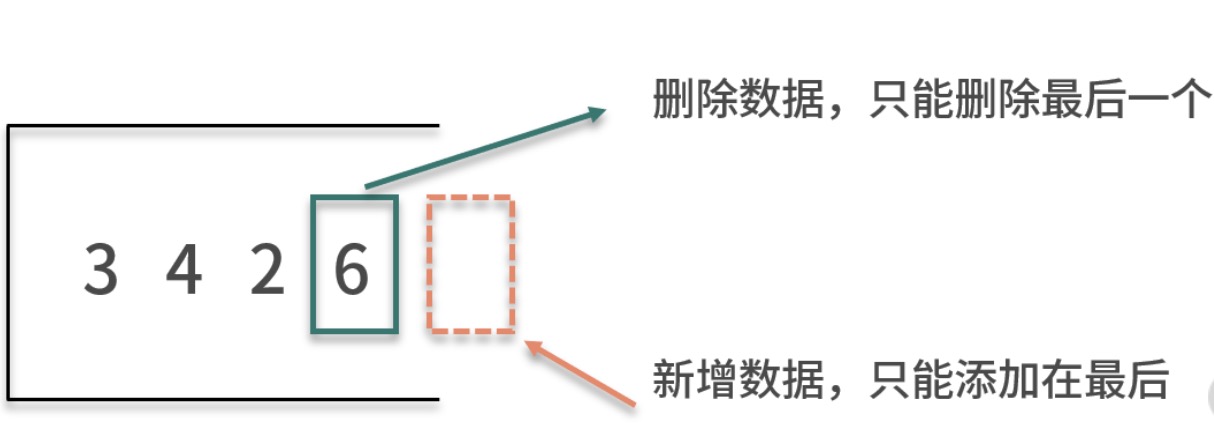
因此,栈是一种后进先出的线性表;栈对数据的处理,就像砖头盖房子,新的砖头总是放在最上面,拆房子也是需要从上往下拆砖头
比如浏览器的后退功能,就是一个典型的后进先出的场景
# 5-3 栈的基本操作
对于栈的新增操作,我们通常也叫做push或压栈
对于栈的删除操作,我们通常也叫做pop或出栈
# 5-4 顺序栈
- 栈的顺序存储可以借助数组来实现,一般会把数组首个元素存在栈底,最后一个元素放在栈顶;
- 定义top指针来指示顶元素在数组中的位置
- 一般以top是否为-1来判定栈是否为空栈
- 当定义了栈的最大容量为StackSize时,则栈顶必须小于StackSize
- 当需要新增数据元素,即入栈操作时,就需要将新插入元素放到栈顶,并将栈顶指针增加1
- 删除数据元素,即出栈操作,只需要top - 1 就可以了
- 查找数据元素,栈没有额外改变,和线性一样,需要遍历整个栈完成查找
# 5-5 链栈
- 对于栈链,新增数据的压栈操作,与链表最后插入的新数据基本相同,需要额外处理的是栈的top指针
- 插入新的数据,需要让新的结点指向原栈顶(即top指针指向新的对象),再让top指针指向新结点
- 在链式栈进行删除操作时,只能在栈顶部进行删除
- 链式栈新增删除时,没有做任何循环操作,所以时间复杂度为O(1)
- 链式栈的查找操作,和其他链表没有区别,都需要循环遍历整个栈来完成基本的查找
- 不管是顺序栈还是链栈,数据的新增删除查找与线性表的操作原理极为相似,时间复杂度也完全一样,都依赖指针
- 区别在于:新增删除的对象,只能是栈顶的数据结点
# 5-6 栈的案例
# 5-6-1 例一
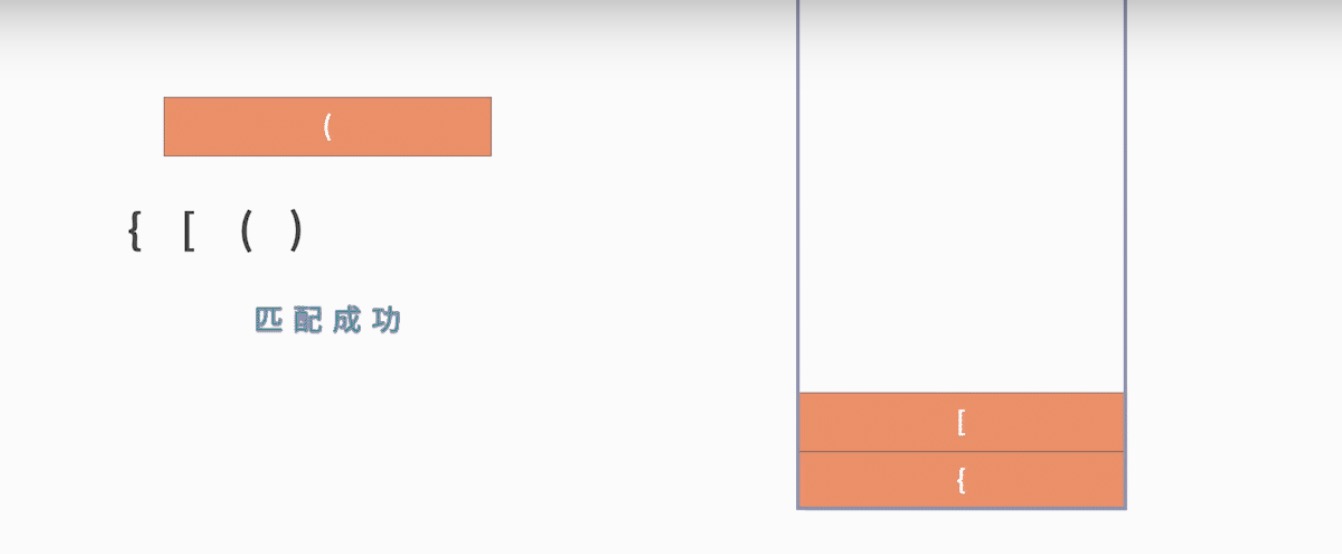
给定一个只包括'(',')','{','}','[', ']'的字符串,判断字符串是否有效
有效的字符串必须满足:左括号必须与相同类型的右括号匹配,且必须按照正确的顺序匹配
例如,{ [ ( ) ( ) ] } 是合法的,而 { ( [ ) ] } 是非法的。
具体做法:
- 从左到右遍历字符串,出现左括号时,压栈;出现右括号时,出栈
- 判断当前是右括号,和被出栈的左括号是否互相匹配一对,若不是,则字符串非法
- 当遍历完成之后,如果栈为空,则合法
# 5-6-2 例二 浏览器的前进后退功能
- 为了支持前进和后退,需要维护两个栈
- 当用户访问可一个新页面,则对后退栈进行压栈操作
- 当用户后退一个页面,则后退栈进行出栈,同时前进栈执行压栈
- 当用户前进了一个页面,则前进栈出栈,同时后退栈压栈
# 5-7 总结
- 栈继承了线性表的优点和不足,是个限制版的线性表
- 限制的功能是;只允许数据从栈顶进出,即后进先出
- 对数据的删除和新增,时间复杂度均为O(1)
- 在查找数据时,和线性表一样,都需要全局遍历进行,所以需要O(n)的时间复杂度
- 栈有后进先出的特征,如果需要频繁新增删除,且具备后来居上的相反关系,栈就是一个不错的选择
- 浏览器的前进后退,括号匹配等,栈在代码编写中存在广泛应用